
Scary but fascinating stuff.
Here's an example, grabbed from one of a great many sudoku internet sites. So there are 9 blocks of size 3 x 3, with some given numbers in given positions, but with blanks waiting for the clever puzzler to fill in the rest. Each 3 x 3 block should contain the numbers 1, 2, 3, 4, 5, 6, 7, 8, 9, and the challenge is to organise these such that each row and each column of the resulting 9 x 9 matrix contains precisely these 1-to-9 numbers.
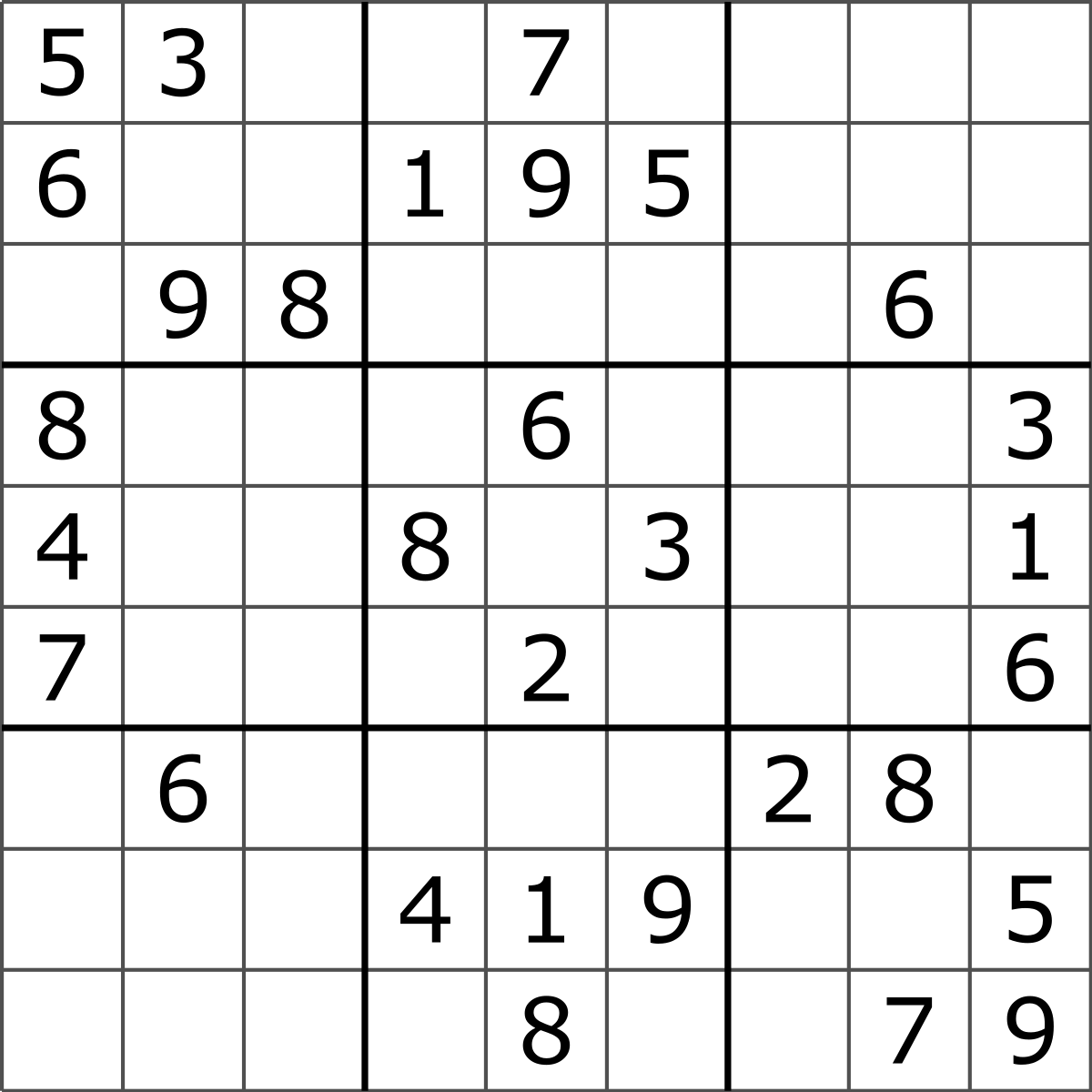
My first-ever sudoku puzzle.
A statistical take
I've never solved a sudoku puzzle before, and to me it looks dauntingly complex (though presumably not to millions of seasoned sudoku puzzlers, and I'm told the one I grabbed here is not among the hard ones). There are 4, 5, 8 missing numbers for the first three blocks, those of the first row, which means there are
\(4!\cdot5!\cdot8!=24\cdot120\cdot40320=116121600\)
ways of organising these missing numbers alone. In total, for the nine blocks, with missing pieces numbering 4, 5, 8, 6, 5, 8, 8, 5, 4, there's an astronomical number of $8.388\cdot10^{23}$ different possibilities. And only one of these is the right solution to the puzzle.
Rather than (a) going through all possibilities, which would take my laptop longer time than the remaining life-time of the sun and the moon, or (b) trying to learn to be clever at these things, I choose (c) to attempt to be clever in a different and statistical way, by building a good enough probability model, on this enormous sample space of 9 x 9 sudoku tables, favouring outcomes which can't be very far from the Real Thing, and (d) to throw a Markov chain at it, to read off those simulated sudoku tables which have high probability under my constructed model.
First, the sample space for my model is the colossal one consisting of all 9 x 9 matrices $x$, where each of the nine 3 x 3 blocks consists of the natural numbers 1-to-9, and with the 30 fixed numbers in their fixed positions, as given by the puzzle. So for the upper-left corner block, I can shuffle the missing numbers 1, 2, 4, 7 around on the four available places, etc. The size of the full sample space is the gargantuan $8.388\cdot10^{23}$ mentioned above. Then, my probability model, which should favour "good attempts at solving the puzzle". I make it
\(f(x)=(1/k)\exp\{-\lambda Q(x)\},\)
where $Q(x)$ is constructed to be zero for the perfect solution and otherwise with low values for matrices that are not too far off. Here $\lambda$ is a positive tuning parameter, and $k$ is the normalisation constant, a mathematical necessity, though it is impossible to compute, since it is a sum of astrologically many terms. As we shall see, we can do the sampling without knowing its value, however. There are many $Q(x)$ functions to choose from, perhaps more clever than my own brute-force version, which is
\(Q(x)=\sum_{i=1}^9 r_i(x) + \sum_{j=1}^9 c_j(x), \)
where
\(r_i(x)=\sum_{j=1}^9 |{\rm sort}(x[i,\cdot])_j-j|,\)
a function which is zero if and only if row $i$ precisely contains the 1-to-9 numbers, and similarly with the column scores $c_j(x)$. If the sudoku table $x$ is not far from the perfect $x^*$, the $Q(x)$ will be low; correspondingly, $Q(x)$ will be high if rows and columns of $x$ are some distance away from containing the 1-to-9 numbers. There is only one 9 x 9 sudoku table, say $x^*$, which attains $Q(x)=0$.
Markov chains
The point now, theoretically and practically, is that I can manage to sample sudoko tables from the $f(x)$ probability distribution, using an appropriately constructed Markov chain of constrained 9 x 9 matrices. Perhaps 99.999999 percent of the umpteen fantasticatillion matrices have very low probabilities, under my $f(x)$ model. So if I succeed in simulating a sequence of outcomes from the model, what I will see are 9 x 9 sudoku tables with low scores of $Q(x)$, i.e. which are not far from the sudoku solution $x^*$. I manage this by setting up a perhaps very long Markov chain of 9 x 9 matrices, say $x_1,x_2,x_3,\ldots$, where (a) the next outcome $x_{t+1}$ should be easy to generate given the present $x_t$, and (b) the equilibrium distribution should be precisely the $f(x)$ above.
What I do is to (i) start anywhere, e.g. by filling in the remaining numbers 1, 2, 4, 7 randomly in the upper-left block, etc.; (ii) generate simple proposals, say $x_{\rm prop}$ after having seen $x_{\rm prev}$, with `prop' and `prev' indicating the proposal and previous sudoku table of the Markov chain; and then (iii) accepting or rejecting these proposals with fine-calibrated probabilities. This last step (iii) involves accepting the proposal with probability
\(\eqalign{ {\rm pr} &=\min\{1,f(x_{\rm prop})/f(x_{\rm prev})\} \cr &=\min\{1,\exp[-\lambda\{Q(x_{\rm prop})-Q(x_{\rm prev})\}]\}, \cr}\)
and letting $x_{t+1}$ remain at the previous $x_t$ with the complementary probability $1-{\rm pr}$. If the generated proposal has lower $Q(x_{\rm prop})$ than the previous $Q(x_{\rm prev})$, then it is automatically accepted as the next matrix in my chain of attempted sudoku solutions. If it is bigger, and hence looking worse, from the sudoku puzzle perspective, it may still be accepted, but then with a certain well-chosen probability, namely $\exp(-\lambda)$ raised to a certain power, as per the recipe described. Note that the awkard normalisation constant $k$ has dropped out of the algorithm. I do step (ii) by randomly selecting one of the nine 3 x 3 blocks, then pointing to two of the moveable unknowns (inside that block), and ordering these two guys to change places. I've accomplished this in brute-force fashion, with a decent amount of book-keeping in my R code, and it's not at all optimised for speed – but it works, and can churn through a hundred thousand iterations in two minutes on my laptop.
Theory for stationary Markov chains, with theorems from the Kolmogorov era of the 1930ies, now guarantee that the chain I've described has a unique equilibrium distribution, namely & precisely, the intended $f(x)$. The essence here is that with $\pi(x'\,|\,x)$ denoting the transition probability for the chain, the chance of the next matrix being $x'$ when starting from $x$, we do have
\(f(x)\pi(x'\,|\,x)=f(x')\pi(x\,|\,x') \)
for all matrices $x,x'$ in the sudoku sample space.

Long sudoku Markov chain to see when $Q(x)$ hits zero, after which I can read off the solution $x^*$.
With a bit of twiddling and R-fumbling and fine-tuning for $\lambda$ I got the chain to work, the $Q(x)$ really visited zero before I could say `half a million', and found the solution, lo & behold:
\(\matrix{ \pmatrix{ 5 & 3 & 4 \cr 6 & 7 & 2 \cr 1 & 9 & 8 \cr} \pmatrix{ 6 & 7 & 8 \cr 1 & 9 & 5 \cr 3 & 4 & 2 \cr} \pmatrix{ 9 & 1 & 2 \cr 3 & 4 & 8 \cr 5 & 6 & 7 \cr} \cr \pmatrix{ 8 & 5 & 9 \cr 4 & 2 & 6 \cr 7 & 1 & 3 \cr} \pmatrix{ 7 & 6 & 1 \cr 8 & 5 & 3 \cr 9 & 2 & 4 \cr} \pmatrix{ 4 & 2 & 3 \cr 7 & 9 & 1 \cr 8 & 5 & 6 \cr} \cr \pmatrix{ 9 & 6 & 1 \cr 2 & 8 & 7 \cr 3 & 4 & 5 \cr} \pmatrix{ 5 & 3 & 7 \cr 4 & 1 & 9 \cr 2 & 8 & 6 \cr} \pmatrix{ 2 & 8 & 4 \cr 6 & 3 & 5 \cr 1 & 7 & 9 \cr} \cr}\)
A few remarks
A. A.A. Markov (1856-1922) invented Markov chains in about 1910, and the world's first serious data analysis using Markov chains was carried out by Markov himself, in 1913. Amazingly, he went through the first 20,000 letters of Pushkin's epic poem Евгений Онегин, keeping track of how vowels and consonants followed consonants and vowels, the point being to clearly demonstrate that the vowel-consonant gender of the letters of words are not statistically independent. See more discussion on this in N.L. Hjort and C. Varin's paper ML, PL, QL in Markov chain models (Scandinavian Journal of Statistics, 2008), where we also study longer-memory processes. So Markov's sample space, for that application, had two elements. I imagine that he would have been delighted to see how I can use his chains, in enormously big sample spaces, to read off solutions to highly complicated puzzles, like sudoku and magic squares.
B. There would be several ways to improve my R code, both algorithmically and mathematically. To do the book-keeping I needed to invent ${\tt blocktolist}(x)$ and ${\tt listtoblock}(x)$ functions, and I do the $Q(x_{\rm prop})-Q(x_{\rm prev})$ computations by straightforward brute force. It is clear that if a puzzler sees some clear numbers to fill in for the blanks, those can be plugged in, simplifying not the algorithm per se but the speed with which it lands at zero. Yet other number theoretic based tricks could be built into the algorithm and my R code, since some of the choices made in the $x_{\rm prop}$ step are sillier than others, but the relative statistical beauty of the Nils Sudoku Solver™ is its simplicity and generality. In particular, the code doesn't know, and doesn't care, whether the sudoku puzzle is seen as `hard' or `relatively easy'.
C. The role of the $\lambda$ parameter is partly to dictate the sharpness of the probability distribution around its peak, the $x^*$ solution. It sounds good to allow a somewhat large $\lambda$, since that means that once you're near the peak, you'll never slide down again. At the same time one needs $\lambda$ to be small enough to allow the chain to jump around a bit for a while. There's a possibility of getting trapped close to a fine-looking mountain, which indeed is tall (perhaps $Q(x)$ is as low as 8 or 6 or 4 or 2), but not the same as the Very Tallest One, the sudoko solution $x^*$. Perhaps the sudoku chain is labouring away, for a while, climbing K2 or Kangchenjunga or Lhotse, but eventually it should discover that there's a Mount Everest elsewhere, and give itself the chance to backtrack and climb upwards again. For these reasons $\lambda$ should be somewhat small.

The sudoku Markov chain will eventually find the tallest peak. My Himalayan metaphor is misleading regarding the size of the problem; the sample space in which the chain selflessly struggles, with a hundred thousand attempts per minute, is astronomical rather than merely planetary big.
There are mathematical theorems securing that the random chain will succeed in finding the Tallest Peak in the World, with high enough probability, by having $\lambda$ start small and then very gradually increase, but it is difficult to translate such theorems into very clear guidelines. Based on having solved just a few sudoko puzzles, I think the Tryle N. Error attitude is fine, perhaps with $\lambda=1$ as an ok start value (with the $Q(x)$ function used above).
D. The $f(x)=(1/k)\exp\{-\lambda Q(x)\}$ model has been constructed to favour good-looking sudoku tables, not far off from the final solution. I'm free to also consider negative $\lambda$ values, however, which seriously turns the tables, suddenly favouring high $Q(x)$ values rather than low ones. The Markov chain apparatus still obeys, and can churn out clearly horrible-looking sudoku tables, as far away from the genuine solution as possible, in its still enormous space of possibilities. Here's one such, generated by letting the chain roll on for a while, with a negative model tuning parameter. It's still a sudoku table, with 1-to-9 in each 3 x 3 block, but the rows and columns of the 9 x 9 table are nine far cries away from being what the puzzler wants:
\(\matrix{ \pmatrix{ 5 &3 &1 \cr 6 &4 &2 \cr 7 &9 &8 \cr} \pmatrix{ 2 &7 &6 \cr 1 &9 &5 \cr 4 &3 &8 \cr} \pmatrix{ 1 &5 &2 \cr 3 &9 &4 \cr 8 &6 &7 \cr} \cr \pmatrix{ 8 &9 &3 \cr 4 &6 &1 \cr 7 &5 &2 \cr} \pmatrix{ 7 &6 &9 \cr 8 &1 &3 \cr 4 &2 &5 \cr} \pmatrix{ 7 &9 &3 \cr 2 &8 &1 \cr 4 &5 &6 \cr} \cr \pmatrix{ 8 &6 &1 \cr 5 &3 &2 \cr 7 &9 &4 \cr} \pmatrix{ 3 &2 &6 \cr 4 &1 &9 \cr 5 &8 &7 \cr} \pmatrix{ 2 &8 &3 \cr 1 &6 &5 \cr 4 &7 &9 \cr} \cr}\)
E. There are not surprisingly various mathematically based non-random algorithms, which work for classes of sudoku puzzles (try the net). I have not attempted to look into these, and neither have I tried to compare my Markov chains with any of those. I expect that when a non-random algorithm works, then it will work more efficiently than my after all simple Markov chains. But my construction is pleasantly clear (well, in principle, give and take some plundering work to get the R code in shape), is fun to watch in action, and working through a few million steps is easier than attempting to search more brutally through bigger parts of the $10^{23}$ possible cases.
F. Also, the probability model and Markov chains approach can be amended or extended to solve various other puzzles and high-dimensional combinatorial challenges. In an accompanying FocuStat blog post, The Magic Square of 33, I use similar models and simulation methods to find supermagical squares. This is a good exercise, for readers of this blog post: Try to construct an 8 x 8 square, using the natural numbers 1 to 64, such that each row and each column, and both diagonals, sum to 260, and also such that the sums for the four corner 4 x 4 blocks, as well as for the middle 4 x 4 block, are all equal to 520. Using the indicated method I managed to find this table:
\(\pmatrix{ 27 & 50 & 6 & 48 & 43 & 39 & 46 & 1 \cr 3 & 56 & 60 & 8 & 14 & 49 & 61 & 9\cr 11 & 28 & 45 & 53 & 24 & 40 & 25 & 34\cr 35 & 42 & 7 & 41 & 16 & 36 & 19 & 64\cr 22 & 17 & 44 & 26 & 54 & 13 & 21 & 63\cr 59 & 5 & 33 & 57 & 29 & 2 & 37 & 38\cr 52 & 32 & 55 & 12 & 62 & 23 & 4 & 20\cr 51 & 30 & 10 & 15 & 18 & 58 & 47 & 31\cr}\)
G. This FocuStat blog post is more probabilistical than statistical in nature. I have not constructed or fitted models to data, but invented probability models to help me search for the mini-needle in the tera-haystack. Yet there are important application areas, with complex and massive data, like images and texts, where models of the type
\(f(x)=(1/k)\exp\{-\lambda^{\rm t}Q(x)\} =(1/k)\exp\Bigl\{ -\sum_{j=1}^p \lambda_jQ_j(x) \Bigr\}\)
are useful, typically with a multidimensional $Q(x)=(Q_1(x),\ldots,Q_p(x))$ and hence statistical model parameters $\lambda=(\lambda_1,\ldots,\lambda_p)$, say. If you see photos of seven thousand men, or dogs, models could be built of this type, with specially designed $Q_j(x)$ functions, in order to look for differences, or signs of homogeneity, or to analyse the levels of variation. Such applications would then involve estimating and assessing the $\lambda$ parameters, via frequentist or Bayesian setups. Tackling the issues would again involve running Markov chains.
I thank Céline Cunen for valuable comments on some of the aspects taken up in this FocuStat blog post.
Log in to comment
Not UiO or Feide account?
Create a WebID account to comment