Det faktum kan vi avsløre ved hjelp av den statistiske metoden prinsipalkomponent-analyse eller PCA, etter det engelske navnet. Metoden tar de sentrerte variablene (slik at gjennomsnittet for hvert parti ikke har noe å si) og konstruerer en sum score der variablene vektes ulikt - såkalte prinsipalkomponenter (Jolliffe, 2002). Vekting av variablene velges slik at variabiliteten til scoren blir størst mulig:
\(Z_{i1}= v_1^T X_i= \sum_{j=1}^p v_{1j}X_{ij}, \quad v_1 =\arg\max_ {\alpha} \text{Var}(\alpha^T \mathbb X), \| \alpha \|=1\).
Så kan man konstruere flere sett med scorer ved å kreve at vektingene og komponentene skal være uavhengige eller ortogonale med hverandre.
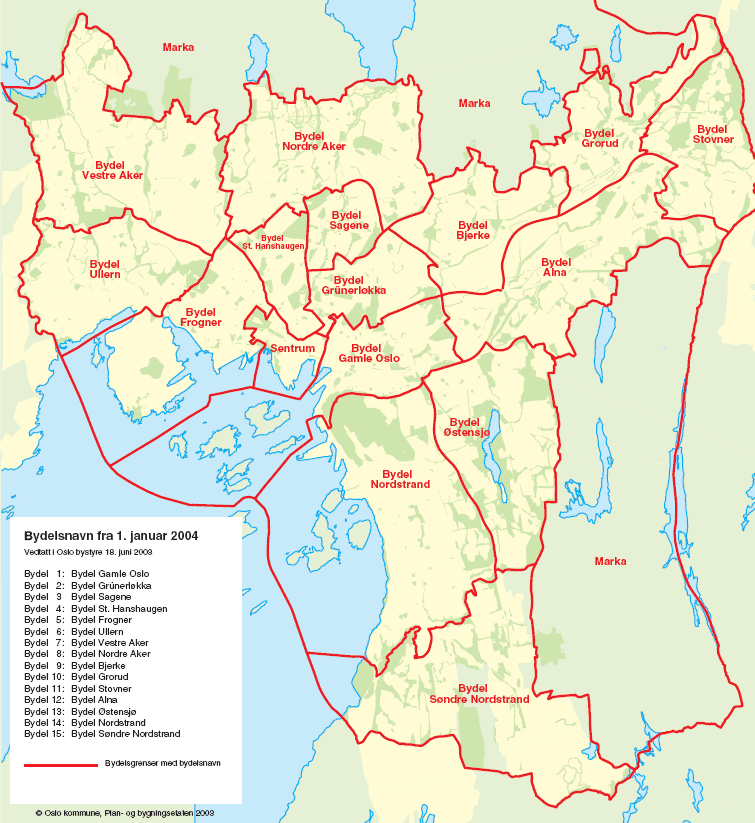
Hvis vi bruker denne metoden på stemmedataene, viser det seg at den første prinsipalkomponenten forklarer 76 % av variasjonen i dataene, mens den andre komponenten, som er uavhengige av den første, forklarer 22 %. Tilsammen forklarer de to første komponentene hele 98 % av variasjonene i stemmemønsteret. Vi kan dermed plotte kun den første og andre komponenten mot hverandre, og likevel få oversikt over neste hele stemmemønsteret.
Det er tydelig at de vestlige bydelene med Nordstrand samler seg til høyre, sentrumsbydelene øverst på midten og de østlige bydelene i nedre venstre hjørne. Men hva uttrykker denne klumping av de ulike bydelene? For å tolke de ulike komponentene kan man se på hvordan de ulike partiene vektes: I den første komponenten er det i all hovedsak kun en stor negativ vekt for Arbeiderpartiet og en stor positiv vekt for Høyre. Det betyr at Høyre får en større andel stemmer, hvis man beveger seg til høyre i bildet, og Arbeiderpartiet får en større andel stemmer, hvis man beveger seg mot venstre. Vi kan dermed tenke oss at denne komponenten uttrykker høyre-venstreaksen som finnes i politikken. Siden Ap og Høyre er de to største partiene, illustrerer det også hvorfor komponenten forklarer så mye som 76% av variasjonen i stemmene.
I den andre komponenten har vektene mer jevnt fordelt utover partiene, med MDG som størst enkeltvekten i positiv retning. Rødt, SV og Venstre har alle samme positive vekting, mens AP, Høyre og FRP har negative vekter. Denne komponenten ser ut til å overskride den klassiske høyrevenstre-aksen og kan i større grad uttrykke noe annet som for eksempel aldersforskjeller. Miljøpartiet De Grønne står altså sterkest i bydelene øverst i plottet og får færre stemmer jo lenger ned man kommer.
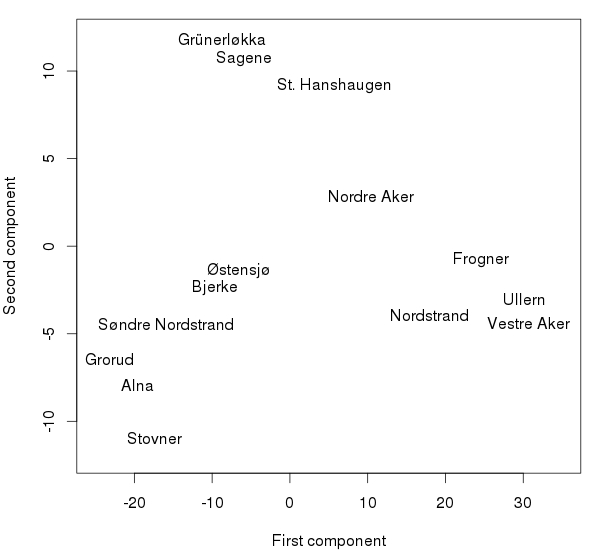
I den første analysen brukte vi de originale sentrerte prosentene, men vi kan også skalere dataene slik at de mindre partiene får mer å si i det store bildet. Da ser vi kun på korrelasjonen mellom partiene og alle variablene vil ha en varians lik 1. Ved en slik analyse trenger vi flere komponenter for å forklare det samme mønsteret. Den første komponenten vil nå forklare 47 % av variasjonen, mens den andre forklarer 36 % og den tredje hele 12 %. Men fortsatt trengs det kun 3 komponenter(!) for å forklare hele 96% av det store bildet.
Etter dataskaleringen er ikke komponenten som uttrykker høyrevenstre-aksen lenger den viktigste. Istedenfor uttrykker den første komponenten en positiv vekt for Venstre, MDG, Rødt og SV, og en sterk negativ vekt for Ap og Frp. Det er virker igjen å være knyttet opp mot alder eller forskjeller mellom singlehushold og barnefamilier. Videre uttrykker en negativ andrekomponent et sterkt Høyre (og noe Venstre), mens en positiv andrekomponent vekter både Rødt, SV og Arbeiderpartiet. Her finner vi altså igjen den klassiske høyre-venstreasken.
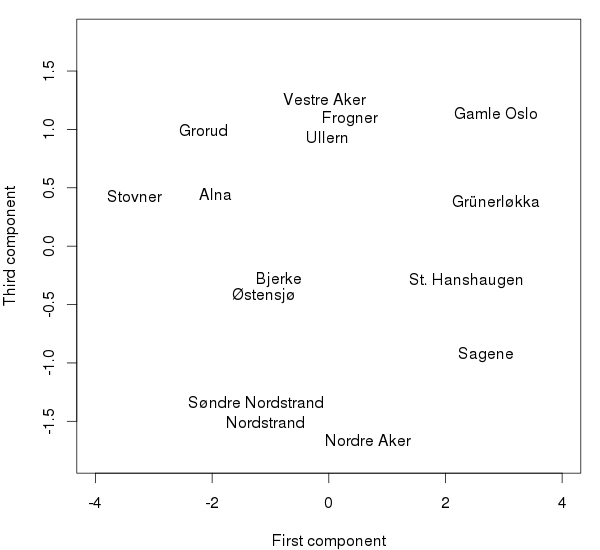
Det mest interessante er likevel hva som finnes i den tredje komponenten, som forklarer hele 12% av variasjonen. Det avsløres i en viss grad ved å plotte første og tredje komponent sammen.
I dette plottet opphører de tradisjonelle østvest-aksene, og nye gruppestrukturer ser ut til å oppstå. Svaret bak dette mønsteret er at den tredje komponenten nesten utelukkende uttrykke stemmene til KrF. Nederst i plottet er Kristelig Folkeparti aller sterkest, mens stemmeprosenten synker jo høyre opp i plottet man kommer. Dermed er Nordre Aker ikke lenger en ``midt-i-alt''-type bydel, men havner aller nederst sammen med Nordstrand og Søndre Nordstrand. Dette plottet kan dermed vise fordelingen av bydelene med en alderskomponent langs den horisontale aksen og en potensiell kristenreligiøs komponent langs den vertikale aksen.
This is partly to check out the "comment" function for the FocuStat blog, but also to ask a perhaps simple follow-up question regarding Kristoffer's blog post: How stable are the above results (and associated interpretations) to variations over time? Can important trends be spotted (and interpreted) by using the PCA analysis machinery for Oslo election data 2015, 2013, 2011, 2009, 2007?
Log in to comment
Not UiO or Feide account?
Create a WebID account to comment