Nettsider med emneord «Deep Learning»

Our last LATICE seminar for this semester will include a presentation on snow impurities by using deep learning by our guests and a round of updates from the LATICE participants. Join us on June 17th, 2024 at 13:00.




Neural network architectures currently used for histopathology were developed for natural images (not medical ones). Some of these architectures have been shown to have inductive biases for natural images, i.e., the neural network's architecture has some information about the natural images. These biases can be very helpful for processing natural images. This project aims to find architectures with an inductive bias for histopathological images. We will do it in an automated way (using neural architecture search) instead of trying to build an architecture manually.
This work will investigate using diffusion models to create superresolution multispectral images.
Simulating the propagation of waves is key from several aspects of acoustic imaging, for example, in the evaluation of various image reconstruction algorithm, or even as an integrated part of the signal processing applied when generating an image from recorded time signals.

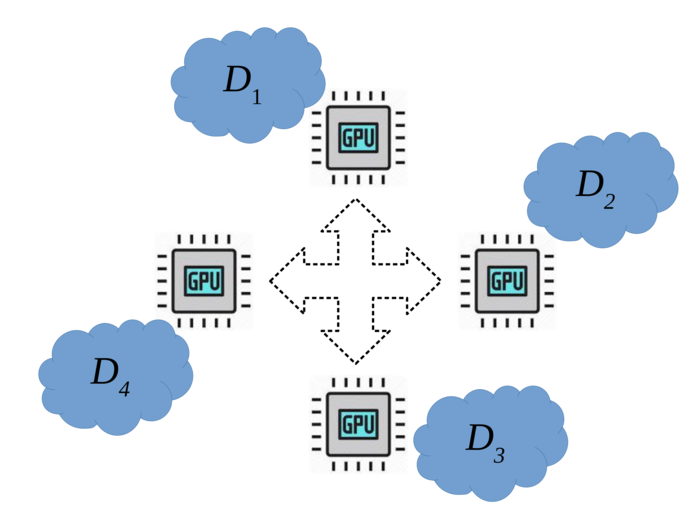
In this project, we modify adaptive variants of unbiased quantization schemes tailored to general variational inequality (VI) problems including those with convex-like structures, e.g., convex minimization, saddle-point problems, and games [4–6] with several applications such as auction theory [7], multi-agent and robust reinforcement learning (RL) [8], adversarially robust learning [9], and generative adversarial networks. In particular, our goal is to design novel adaptive and layer-wise compression schemes tailored to tasks beyond supervised learning building on our recent work on SOTA compression schemes for deep learning [1,10].




.jpg?alt=listing)



Some people say the future of language modeling lies in processing text as raw sequences of characters. This future has come closer with the recent introduction of the ByT5 language model. Can we use the task of grammatical error correction to assess its linguistic understanding?


