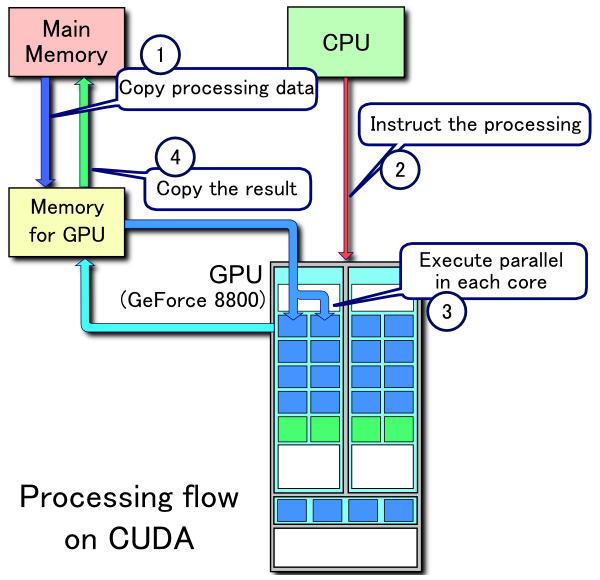
This master project aims to develop a simple-to-use library that helps the programmers to handle data communications that will arise from using a typical GPU-enhanced supercomputer. The usage scenario should cover both single-GPU nodes and multi-GPU nodes. Through using various communication latency hiding techniques, the newly developed library should contribute to improving the achievable performance on such cutting-edge hybrid hardware.
What you will do:
- Test out various techniques for hiding communication latency in the context of hybrid CPU-GPU computing
- Develop a simple-to-use library for data communication that typically arises in scientific code
- Verify the efficiency of the developed library by applying it to existing test cases
What you will learn:
- Parallel programming techniques: MPI, OpenMP and CUDA
- Communication latency hiding techniques
- How to use cutting-edge supercomputers
Qualifications:
- Good (serial) programming skills
- Entrance-level knowledge of numerical methods
- A lot of courage and dedication