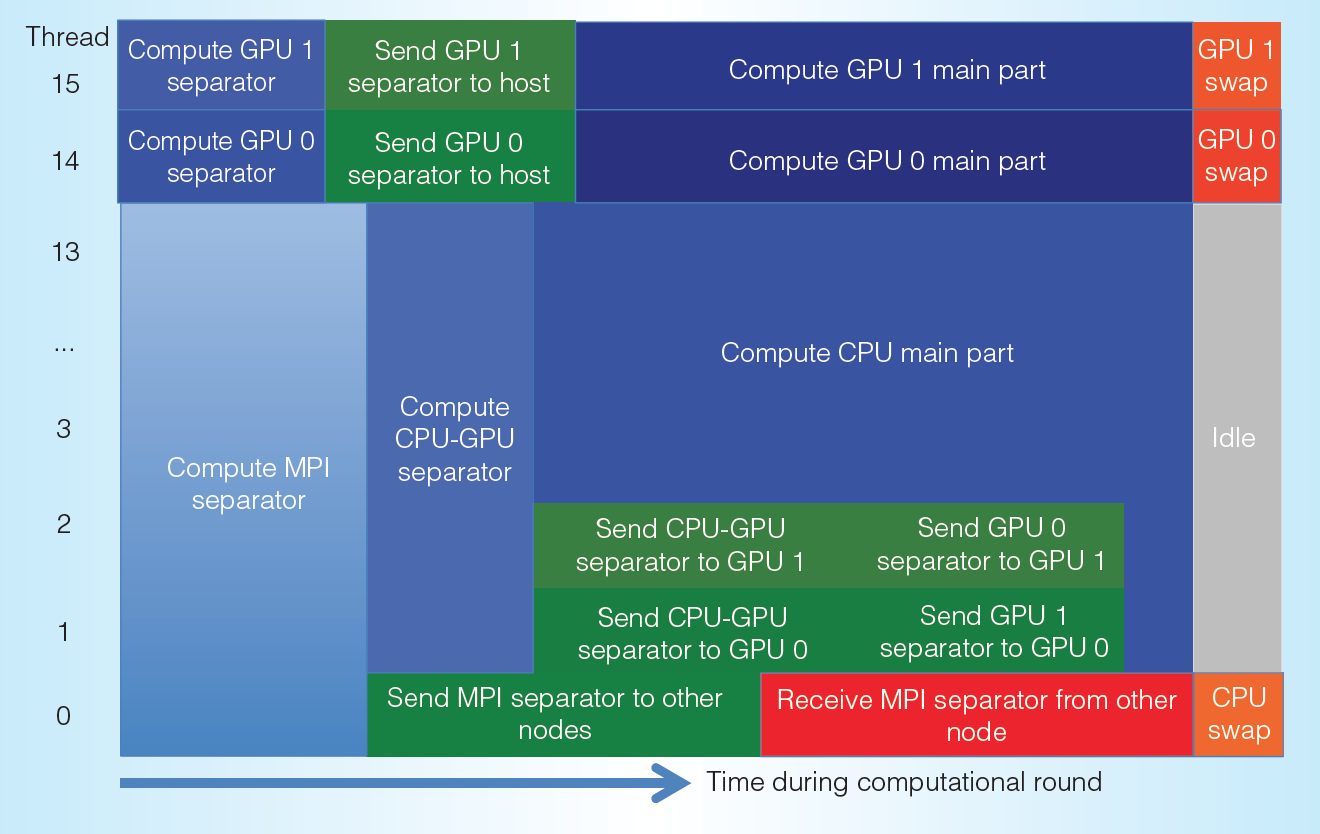
Introduction
Large computing systems of the future are likely to be heterogeneous, that is, containing at least two types of processor architectures. A typical configuration of a future supercomputer is a cluster of compute nodes where each node consists of a host CPU and one or several non-CPU processors (such as GPUs or FPGAs). One of the research questions related to parallel programming of such heterogeneous systems is whether to overlap communication with computation for the purpose of "hiding" the communication overhead. Although communication-computation overlap is an established strategy in traditional pure-CPU parallel programming, its appropriateness in the era of heterogeneous computing requires a new investigation. This is both due to the extra programming complexity that will be induced by implementing communication-computation overlap, and due to the impact of, for example, memory bandwidth contention thus incurred, which may lead to a slower computation speed as a whole.
Goal
This master-degree project aims at a detailed and quantifiable understanding of the impact of overlapping communication with computation on heterogeneous parallel computers. The candidate will start with developing simple synthetic benchmark programs that implement various scenarios of communication-computation overlap, where it should be flexible to control the amounts (and designated segments) of node-to-node and CPU-to-accelerator data communication, as well as CPU-accelerator computation division. These benchmarks will be carefully experimented and time-measured for understanding the potential performance benefits (or disadvantages). An effort will be made to establish performance models related to communication-computation overlap or non-overlap. Another objective of this master-degree project is to summarise some programming guidelines in this regard. The scientific findings will then be tested in several chosen real-world parallel codes.
Learning outcome
The candidate will learn about advanced parallel programming: applicable to both multicore CPUs and at least one non-CPU processor architecture. The candidate will also become an expert on performance profiling and modelling. The candidate will get the chances to be familiarised with real-world parallel codes. The candidate will also be exposed to cutting-edge hardware for parallel computing. All these skills and experiences are highly sought-after expertise of future workforce for scientific/technical computing.
Qualifications required
The candidate is expected to be skilful in technical programming (experience with parallel programming is not required, but preferred). Very important: The candidate must be hard-working and eager to learn new skills and knowledge (such as about basic mathematical modeling).